OpenClaw for Enterprise: Agent Workflows for Research, Automation, and Governed Operations
Zedly AI Editorial TeamMarch 17, 202616 min read
OpenClaw is one of the most capable open-source agent frameworks available: 300K+ GitHub stars, shell access, file system control, browser automation, persistent memory, and cron scheduling. For enterprises, that capability translates to agents that can do real operational work: research competitors, mine data from documents and spreadsheets, monitor social media, automate recurring workflows, and process contracts at scale. The framework is self-hosted, supports multiple model providers, and runs on your infrastructure with no data leaving your environment.
This article covers the enterprise use cases where OpenClaw delivers the most value, practical strategies for controlling costs across many agents, and the governance layer that makes it safe to run autonomous agents in a production environment. The goal is not to convince you that OpenClaw is ready for enterprise (the 300K+ stars and the tool set speak for themselves), but to show you how to deploy it with the right structure, the right cost model, and the right guardrails.
Why Enterprises Are Adopting OpenClaw
The shift from chatbots to agents is the shift from "answer my question" to "do the work." Enterprises are adopting OpenClaw because it crosses that line: agents do not just generate text, they execute shell commands, read and write files, browse the web, query APIs, and maintain memory across sessions. Three architectural choices make OpenClaw particularly suited to enterprise deployment:
Self-hosted, open-source: the gateway runs on your infrastructure. Documents, prompts, tool results, and memory stay in your environment. No vendor lock-in, no surprise data sharing with a SaaS provider. Teams handling regulated data (healthcare, legal, financial, government) can deploy in private clouds or air-gapped networks.
Multi-provider model support: configure OpenAI, Anthropic, Google, or local Ollama models in the same deployment. Route different tasks to different providers based on capability, cost, or data sensitivity requirements. Swap providers without rewriting agent logic.
Persistent memory and cron scheduling: agents remember context across sessions and can run on schedules without human intervention. This is the difference between a tool and a teammate: the agent that monitors your competitors every Monday morning remembers what it found last week.
The contrast with hosted alternatives (ChatGPT Enterprise, Microsoft Copilot) is stark: those products give you a chat interface with limited tool access and no scheduling. OpenClaw gives you a programmable agent with the full tool set, running on infrastructure you control, on a schedule you define.
Company Research and Competitive Intelligence
Enterprise research teams spend significant time on repetitive intelligence gathering: monitoring competitor pricing, tracking SEC filings, reading industry reports, and summarizing market changes. OpenClaw agents automate the collection and synthesis while persistent memory builds an institutional knowledge base over time.
Practical patterns:
Competitor monitoring: an agent browses five competitor pricing pages every Monday, compares current prices to what it remembers from last week, and writes a change summary to a shared report file. The browser tool handles JavaScript-rendered pages that simple HTTP requests miss.
SEC filing extraction: an agent reads quarterly filings, extracts revenue figures, risk factors, and management commentary, then appends structured data to a tracking spreadsheet. Memory lets the agent flag changes from previous quarters automatically.
Industry report summarization: upload a batch of PDFs to the agent's workspace, schedule a cron job to process them overnight, and review the summaries in the morning. The agent reads each document, extracts key findings, and produces a consolidated brief.
The key advantage over manual research is not just speed but consistency: the agent checks the same sources, applies the same extraction logic, and remembers the same historical context every time it runs.
Data Mining and Analysis
OpenClaw agents have direct access to the file system and shell, which means they can read CSVs, run Python scripts, query databases, and process spreadsheets without relying on limited file-upload interfaces. For enterprises sitting on large volumes of operational data, this is the difference between "upload one file at a time" and "point the agent at a directory and let it work."
Vendor invoice profiling: an agent reads 50 invoices from a shared folder, extracts amounts, dates, and vendor names, flags anomalies (duplicate amounts, unusual payment terms, missing fields), and produces a summary report.
Spreadsheet analysis: an agent runs a Python script via the exec tool to profile a dataset: column types, missing values, outliers, and distribution statistics. No need to install data science tools on your laptop; the agent handles the computation.
Database queries: for teams that expose read-only database access to the agent, it can run SQL queries, join tables, and summarize results in natural language, bridging the gap between raw data and business insight.
The exec tool is the workhorse here: it lets agents run arbitrary scripts, which means any analysis you can express in Python, R, or a shell script can be delegated to an agent and scheduled to run on a recurring basis.
Social Media and Community Monitoring
Brand mentions on Reddit, X/Twitter, and industry forums are scattered, unstructured, and time-consuming to track manually. OpenClaw's browser tool lets agents navigate these platforms, extract content, and summarize sentiment without requiring API access or rate-limit negotiations.
Reddit research: an agent browses relevant subreddits daily, extracts posts mentioning your brand or product category, classifies sentiment, and writes a daily digest. Persistent memory lets it track trends week over week: "mentions of [competitor] increased 40% this week, mostly in threads about pricing."
X/Twitter monitoring: an agent tracks industry conversations, competitor announcements, and customer feedback. The browser tool handles the rendering that API-only approaches miss (quoted tweets, threaded replies, embedded media context).
Forum and review site tracking: for B2B companies, industry-specific forums (Hacker News, niche Slack communities, G2 reviews) contain high-signal feedback. An agent can monitor these sources on a schedule and surface the relevant threads.
Cron scheduling is essential for social monitoring: you want the agent to check daily or weekly without manual triggering. Each run produces a distinct session that appears in the audit log, so you can verify what the agent accessed and when. For a deeper dive into trend discovery, sentiment tracking, and other marketing-specific workflows, see our guide to OpenClaw for marketing.
Document Processing and Contract Review
Enterprises process contracts, agreements, and compliance documents at volume. OpenClaw agents can read PDFs, extract clauses, compare terms across agreements, and flag deviations from standard language. Persistent memory adds a dimension that batch-processing tools lack: the agent recalls patterns from prior contracts and applies that institutional knowledge to new reviews.
Contract clause extraction: an agent reads a vendor agreement, identifies key clauses (termination, liability, indemnification, change of control), and produces a structured summary. For teams reviewing dozens of contracts per quarter, this replaces hours of manual scanning.
Cross-agreement comparison: upload multiple agreements to the workspace and ask the agent to compare terms across all of them. Which vendor has the most favorable payment terms? Which agreement has a non-standard liability cap? The agent produces a comparison table.
Batch processing with cron: schedule a nightly job that processes all new documents in an intake folder, extracts metadata, and writes results to a tracking spreadsheet. By morning, the queue is cleared.
The use cases above are individual workflows. At enterprise scale, the value compounds when multiple agents run coordinated tasks on schedules:
Weekly vendor spend reconciliation: an agent reads this week's invoices from the intake folder, matches them against purchase orders, flags discrepancies, and writes a reconciliation report. The same agent remembers last week's unresolved items and checks if they have been resolved.
Daily operations digest: separate agents monitor competitors, track social mentions, process incoming documents, and profile new data uploads. A summary agent reads all their outputs and produces a single morning brief for the team.
Compliance document preparation: an agent collects evidence from multiple systems (audit logs, access records, policy documents), assembles them into the required format, and produces a draft compliance report for human review.
The pattern is consistent: define the task, assign the model, set the schedule, let the agent work. Persistent memory and cron scheduling turn individual capabilities into sustained operational workflows.
Controlling Costs with Model Routing
Running 20 or 30 agents on schedules adds up fast if every task uses a frontier model. This is the cost lever that most OpenClaw guides do not cover: you can configure different model providers per agent, and the model choice is the single biggest factor in your monthly spend.
OpenClaw's openclaw.json configuration lets you assign models at the agent level. A practical tiering strategy:
Task type
Model tier
Examples
Relative cost
Complex reasoning
Frontier (GPT-4o, Claude Opus)
Contract analysis, strategic research synthesis, multi-step planning
Data scraping, CSV parsing, sentiment classification, log summarization
0.05x - 0.1x
Air-gapped / zero-cost batch
Local (Ollama, llama.cpp)
Internal document processing, classified data, bulk extraction where latency is acceptable
$0 (compute only)
A concrete example: a daily Reddit monitoring agent that scrapes five subreddits and extracts brand mentions. On GPT-4o, that agent might cost $1.50 per run ($45/month). On GPT-4o-mini, the same agent produces equivalent extraction quality for $0.08 per run ($2.40/month). The extraction task does not need frontier reasoning; it needs reliable pattern matching and summarization, which budget models handle well.
The configuration is straightforward. Two agents, two different providers:
The math scales: 30 daily cron agents x 365 days/year means the model choice is the difference between a $500/month bill and a $15,000/month bill for the same set of tasks. Start every agent on the cheapest model that produces acceptable quality, and only upgrade the ones where quality measurably improves.
For many enterprises, the model capabilities are table stakes. The deciding factor is where the data lives and who controls the infrastructure. OpenClaw's self-hosted architecture addresses three enterprise requirements that hosted alternatives cannot:
Data sovereignty: documents, prompts, tool results, and agent memory stay on your infrastructure. No data is sent to OpenClaw's servers (there are none). Model calls go to your chosen provider (or to a local model if you run Ollama), and your data handling policies apply end to end.
Network isolation: for teams handling classified, restricted, or regulated data, OpenClaw can run entirely air-gapped with a local model. No internet connectivity required. This is the deployment model for government agencies, defense contractors, and healthcare organizations with strict data residency requirements.
Compliance alignment: HIPAA, SOC 2, GDPR, and industry-specific regulations require demonstrable control over data processing. A self-hosted deployment with documented data flows and audit trails is easier to certify than a third-party SaaS dependency.
Enterprise DLP tools were built for human-initiated data movements: file copies, email attachments, cloud uploads. Agentic AI breaks that model. An OpenClaw agent reading contracts, extracting terms, and sending the accumulated context to an external model provider creates data flows that traditional endpoint DLP and network CASB tools cannot interpret. The leak vector is not a file transfer; it is a structured API call containing tool results from a dozen autonomous operations.
The architectural response matters. Cloud-hosted DLP proxies that sit between the agent and the model provider can inspect outbound payloads, but they route your sensitive data through third-party infrastructure for scanning. Endpoint agents see file access at the OS level but lack visibility into tool call semantics. The alternative is an on-device execution boundary: a process that sits inside the agent pipeline, scans content locally before it enters the model context, and enforces policy without sending data off-machine.
Zedly Shield uses this on-device approach. The daemon is the process that executes shell commands; the agent cannot bypass it because it depends on it to run tools. The plugin hooks into the gateway to redact sensitive content from tool results before the model sees them. PII, API keys, internal identifiers, and customer-defined deny patterns are all caught at the execution layer, on-device, with zero data sent to third parties. For the full technical breakdown, configuration options, and architectural comparison, see our guide on OpenClaw DLP data loss prevention.
Getting OpenClaw Configured: The Setup Gap
Enterprise teams adopting OpenClaw face a practical problem before they get to governance: getting the framework configured and running. LLM provider API keys, model routing, gateway startup, plugin installation, permissions, and cron scheduling each have multiple failure modes. The documentation covers the concepts, but does not cover every combination of OS, Node version, and plugin configuration that teams encounter in practice.
The Zedly Setup Assistant addresses this directly. An AI-assisted engineer connects to your machine via a secure reverse SSH tunnel, inspects your configuration, and gets everything working in a single 15-30 minute session — including Shield installation, model routing, and a verified first agent run. For enterprise teams deploying across multiple machines, the same process scales to fleet rollouts. See the Zedly Setup service page for details and waitlist. For pre-built workflow templates — including email triage, voice operator, vibe coding, and more — browse the OpenClaw use cases gallery.
Enterprise Security: Why Guardrails Are Not Optional
The same tool access that makes OpenClaw powerful makes it dangerous without controls. An agent that can run shell commands can also run rm -rf /. An agent that can browse the web can navigate to an attacker-controlled page containing injected instructions. An agent processing vendor documents might encounter a poisoned file designed to exfiltrate data through a tool call.
For enterprise deployments, four security gaps need to be addressed:
Uncontrolled tool execution: agents decide which tools to call and with what arguments. Without a policy layer, every tool call is auto-approved.
PII in tool results: agents that read documents, emails, and databases will inevitably encounter sensitive data. Without redaction, that data flows to the model provider in every subsequent prompt.
Prompt injection: content the agent reads (web pages, documents, API responses) can contain hidden instructions that steer subsequent tool calls. This is not theoretical; it is the OWASP Top 10 for LLM Applications risk #1 for agentic systems.
No audit trail: compliance teams cannot accept "trust the model." They need a verifiable record of what agents did, what was blocked, and what data was handled.
This is where runtime governance becomes a requirement, not an option.
How Zedly Shield Hardens OpenClaw for Enterprise
Zedly Shield is a governance plugin that adds five layers of runtime hardening to OpenClaw. It installs with a single command, requires no changes to agent code, and enforces policies locally so that sensitive data never passes through Zedly infrastructure.
Layer
What it does
Enterprise benefit
Tool call blocking
Deny dangerous shell commands before execution
Prevent catastrophic actions from autonomous agents
PII redaction
Scrub emails, SSNs, credit cards from tool results
Data protection before content reaches the model provider
Prompt injection detection
Scan messages and tool results for injection patterns
Contain the #1 OWASP risk for agentic systems
Human approval gates
Queue sensitive operations for human review
Human-in-the-loop for high-risk decisions
Tamper-evident audit log
SHA-256 hash-chained event log, local + dashboard
Compliance evidence for SOC 2, HIPAA, GDPR audits
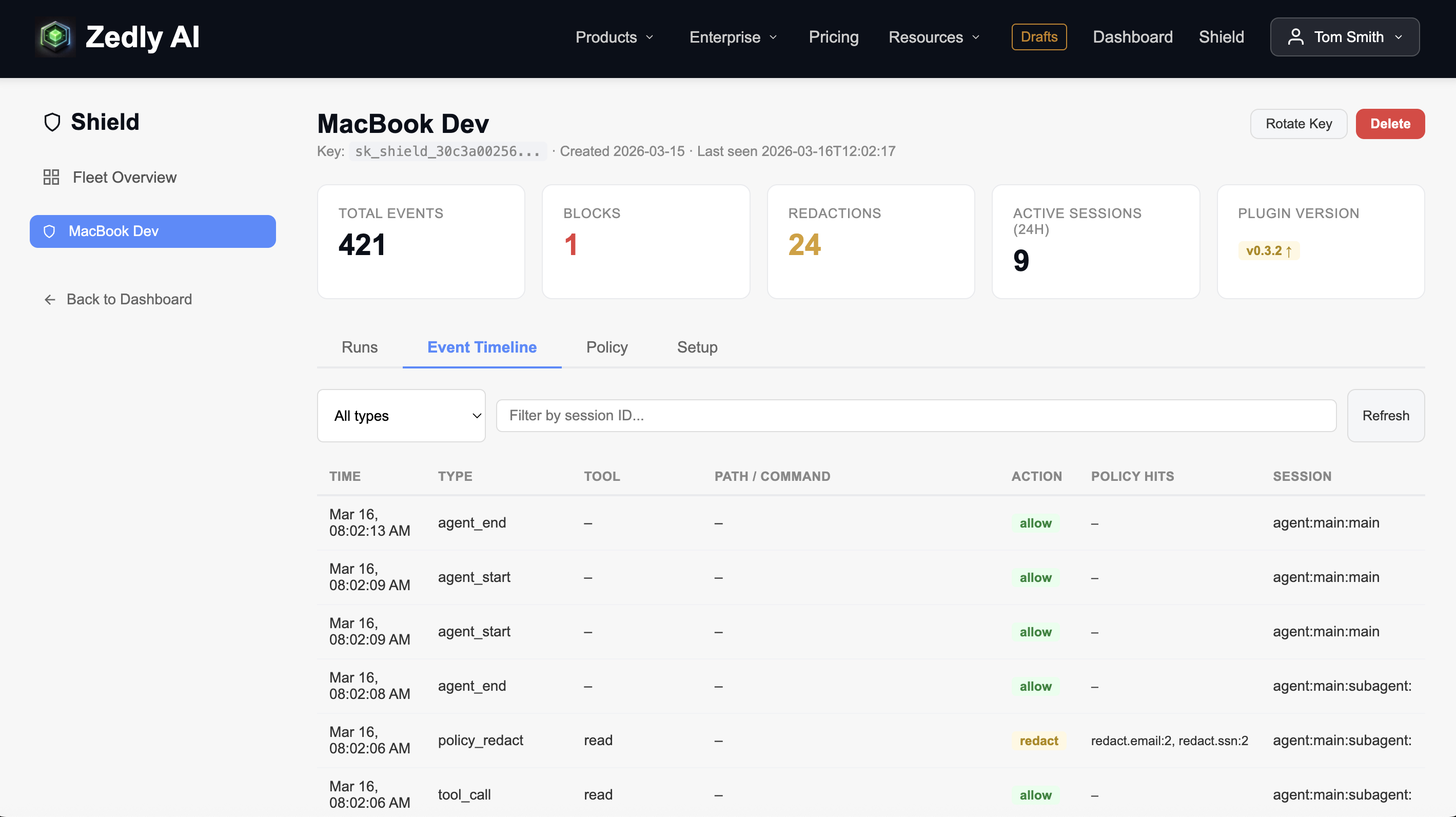
The dashboard provides real-time visibility into agent operations across your fleet: event timelines, run summaries, policy block counts, and redaction events, all filterable by instance, session, tool, and event type.
Zedly Shield dashboard: event timeline showing tool calls, policy blocks, redaction events, and session context across an enterprise OpenClaw deployment (click to enlarge)
Before moving an OpenClaw deployment from pilot to production, verify these items are in place:
Category
Item
Why it matters
Infrastructure
Gateway hosted on enterprise infrastructure (private cloud, VPC, or on-premise)
Data sovereignty and compliance alignment
Model routing
Each agent assigned to the appropriate model tier (frontier, mid, budget, local)
Cost control across agent fleet
Governance plugin
Zedly Shield installed with allowResultModification: true
Runtime policy enforcement and audit logging
Shell blocking
blockDangerousShell: true in Shield config
Prevent destructive commands from autonomous agents
PII redaction
Email, SSN, and credit card redaction enabled
Sensitive data scrubbed before reaching model provider
Injection detection
detectPromptInjection: true
Containment for the #1 agentic AI risk
Audit trail
Log directory writable, API key configured for dashboard forwarding
Compliance evidence and incident investigation
Cron scheduling
Recurring jobs tested with correct model, tool permissions, and memory scope
Unattended agents behave as expected
Monitoring
Dashboard accessible, alert thresholds configured for blocked events
Operational visibility across the fleet
Access control
API keys rotated, least-privilege tool permissions, isolated identities per agent
Limit blast radius of any single compromised agent
Secure Your Enterprise OpenClaw Deployment
Install Zedly Shield to add runtime governance to your OpenClaw agents: tool call blocking, PII redaction, prompt injection detection, and tamper-evident audit logging. One plugin, no code changes, enterprise-grade evidence from the first event.
Yes. OpenClaw supports local model providers through Ollama and other self-hosted inference servers. In an air-gapped deployment, you run both the gateway and the model on the same network with no outbound internet access. Agents function normally with all tools (shell, files, browser on the internal network, memory), and no data leaves the environment. This is the deployment model used by teams handling classified or regulated data where internet connectivity is prohibited by policy.
What is the difference between OpenClaw and ChatGPT Enterprise?
ChatGPT Enterprise is a hosted service where your data goes to OpenAI's infrastructure and the tool set is limited to what OpenAI provides (browsing, code interpreter, file upload). OpenClaw is self-hosted open-source software where you control the infrastructure, the model provider, and the full tool set (shell, file system, browser, memory, HTTP, custom tools). OpenClaw supports multiple model providers simultaneously, persistent memory across sessions, cron scheduling for unattended jobs, and a plugin system for governance. The trade-off is operational responsibility: you manage the deployment, but you own the data and the customization.
How does Zedly Shield handle enterprise compliance requirements?
Shield produces tamper-evident audit events for every tool call, policy decision, and lifecycle event. Each event is linked to the previous one via SHA-256 hash, creating a chain where any modification is detectable. Events include tool name, sanitized arguments, session context, and policy hits, but never raw file contents or PII. This evidence trail supports internal audit processes for SOC 2, HIPAA, and GDPR by providing a verifiable record of what agents did, what was blocked, and what data was redacted. Shield does not certify compliance; it produces the technical evidence that compliance teams need.
Can I run OpenClaw agents on a schedule?
Yes. OpenClaw supports cron-style scheduling where agents run at defined intervals without human intervention. A cron-scheduled agent has access to the same tools and memory as an interactive agent. Common enterprise patterns include daily data collection jobs, weekly report generation, periodic competitor monitoring, and nightly document processing. Each cron run produces a distinct session ID that appears in the audit log and dashboard for tracking and cost attribution.
How do I control costs when running many OpenClaw agents?
The most effective cost lever is model selection per task. OpenClaw lets you configure different model providers for different agents in openclaw.json. Assign frontier models (GPT-4o, Claude Opus) to reasoning-heavy tasks like contract analysis, and use cheaper models (GPT-4o-mini, Claude Haiku, Gemini Flash, or local Ollama) for high-volume repetitive work like data extraction, monitoring, and log summarization. A daily scraping agent on GPT-4o-mini can cost 10 to 20 times less than the same agent on GPT-4o with negligible quality difference for extraction tasks. Tracking spend per job with an event dashboard helps you identify which agents to optimize first.
Ready to get started?
Runtime safety for agentic AI. PII redaction, policy-based blocking, and tamper-evident audit logs for OpenClaw.