OpenClaw Runtime Hardening: How to Control Tool Calls, Approvals, and Audit Logs
Zedly AI Editorial TeamMarch 17, 202613 min read
OpenClaw agents execute shell commands, read and write files, browse the web, query databases, and manage persistent memory. Each of those operations is a tool call, and each tool call is a decision that can go wrong: a poisoned document triggers a destructive command, an unattended cron job exfiltrates data through an HTTP request, or a misconfigured agent overwrites production files. Runtime hardening is the practice of adding control, evidence, and containment layers around those tool calls so that when something goes wrong, the blast radius is limited and the evidence trail is intact.
This article covers the five layers of runtime hardening available for OpenClaw deployments today: tool call blocking, PII redaction, prompt injection detection, human approval gates, and tamper-evident audit logging. Each layer operates at a different point in the tool call lifecycle, and together they form a defense-in-depth stack. Everything described here is implemented in the Zedly Shield plugin and has been validated against a live OpenClaw 2026.3 gateway. For the broader enterprise context, including use cases, cost optimization, and deployment strategy, see our guide to OpenClaw for enterprise. For a deeper look at how these layers fit into a data loss prevention architecture, see our guide on OpenClaw DLP data loss prevention. If you're still getting OpenClaw configured, the Zedly Setup Assistant can handle installation and hardening in a single session.
Why Agentic AI Needs Runtime Hardening
Traditional API security assumes a request-response pattern: validate the input, authenticate the caller, authorize the action, return the result. Agentic AI breaks that pattern. An agent does not make one request; it makes a chain of tool calls, each informed by the results of the previous one. A single user message can trigger a sequence of file reads, shell commands, web fetches, and memory writes before the agent produces a response.
This creates three categories of risk that API-level security does not address:
Autonomous execution: agents decide which tools to call and with what arguments. The user does not approve each step. A cron-scheduled agent may run dozens of tool calls with no human watching the sequence.
Indirect influence: the content an agent reads (documents, web pages, API responses) can contain instructions that steer subsequent tool calls. This is prompt injection at the tool boundary, and the agent does not distinguish data from instructions at the model level. This risk is especially acute for agents that browse untrusted external content daily, such as marketing agents monitoring competitor sites and social media.
No built-in audit trail: OpenClaw's session history was designed for conversation replay, not for a complete operational audit. Cron jobs, sub-agents, and isolated contexts can produce tool calls that do not appear in any searchable log.
Runtime hardening addresses these risks by inserting control points into the tool call lifecycle itself: before the tool executes (blocking, approval), during result processing (redaction, injection detection), and after the event completes (audit logging with integrity guarantees).
The OWASP Top 10 for LLM Applications identifies insecure output handling, excessive agency, and inadequate sandboxing as core risks for systems where LLMs invoke tools. Runtime hardening is the operational response to those risks.
The Five Layers of OpenClaw Runtime Hardening
Each layer hooks into a different point in the OpenClaw event lifecycle. Together they cover the full tool call path from invocation to persistence.
Layer
What it does
OpenClaw hook
Shield config
1. Tool call blocking
Deny dangerous commands before execution
before_tool_call
blockDangerousShell
2. PII redaction
Scrub sensitive data from tool results
tool_result_before_model
redactEmails, redactSSN, redactCreditCard
3. Prompt injection detection
Flag injected instructions in messages and tool results
message_received, tool_result_before_model
detectPromptInjection
4. Human approval gates
Queue sensitive operations for human review
before_tool_call
Roadmap (blocking is live)
5. Tamper-evident audit log
Record every event with SHA-256 hash chain
All hooks
Always on
The layers are independent: you can enable shell blocking without PII redaction, or run injection detection without approval gates. But they are designed to compose: a single tool call can be blocked at Layer 1, and the block event is still recorded at Layer 5 with hash chain integrity. A tool result can be redacted at Layer 2, scanned for injection at Layer 3, and the combined event logged at Layer 5 with both redaction and injection hits in the same record.
Layer 1: Block Dangerous Tool Calls Before They Execute
The before_tool_call hook is the first line of defense. It fires before every tool execution and receives the tool name, arguments, and session context. Shield evaluates the tool call against a set of policy rules and returns either allow or cancel.
Three built-in shell blocking patterns ship with Shield:
Pattern ID
What it matches
Why it is blocked
shell.rm_rf_root
rm -rf / (excludes /tmp/)
Recursive delete from root is catastrophic and rarely intentional
shell.chmod_777_recursive
chmod -R 777
World-writable permissions on a directory tree is a privilege escalation vector
shell.curl_pipe_shell
curl ... | bash
Downloading and executing remote scripts bypasses all local code review
The blocking pattern only applies to tools whose name contains shell or exec. For each matching tool, Shield extracts the command string from the tool arguments (checking command, cmd, input, script, and code fields) and evaluates it against the patterns.
When a tool call is blocked, Shield returns a cancel signal to OpenClaw with a reason string:
The agent receives this message and can choose an alternative approach. The block is also logged as a policy_block event with the matched pattern in the policy hits. For a deeper look at how tool call capture works, see our guide on building an OpenClaw tool call audit log.
Layer 2: Redact PII Before It Reaches the Model
Tool results often contain sensitive data that should not reach the model provider: email addresses in contact lists, SSNs in HR documents, credit card numbers in payment logs. Shield's PII redaction layer scans tool results via the tool_result_before_model hook and replaces detected PII with category tokens before the LLM processes the content.
Three PII categories are supported today:
Emails: detected via regex, replaced with [REDACTED_EMAIL]
SSNs: fixed-format XXX-XX-XXXX patterns, replaced with [REDACTED_SSN]
Credit cards: 13-19 digit sequences with optional separators, replaced with [REDACTED_CC]
Each category is independently toggled in the Shield configuration. Redaction events record per-category hit counts in the policy hits field (e.g., redact.email:2, redact.ssn:1), so the dashboard shows what types of PII were found without revealing the actual values.
For the full design pattern, including tokenization, session-scoped mapping, and rehydration, see our guide on adding PII redaction to OpenClaw.
Layer 3: Detect Prompt Injection at Runtime
Prompt injection is the most insidious threat to agentic systems because the malicious content arrives through normal data channels: a document the agent reads, a webpage it scrapes, or an API response it processes. The agent treats this content as data, but the LLM may interpret embedded instructions as directives.
Shield scans for injection patterns at two points:
Inbound messages (message_received): scanned and logged, but not blocked. Blocking user messages would break legitimate workflows and create false-positive disruptions.
Tool results (tool_result_before_model): scanned, and if injection is detected, a warning prefix is prepended to the result before the model sees it: [SHIELD: content may contain injected instructions].
The scanner runs 30+ regex patterns organized into five categories: instruction override, role hijack, structural markers, exfiltration attempts, and delimiter escapes. Detections are logged as policy_injection events with granular category hits.
Pattern-based detection has blind spots (obfuscated phrasing, adversarial encoding, novel techniques), which is why injection detection is paired with tool call blocking and PII redaction rather than treated as a standalone defense. For the full technical breakdown, see our guide on OpenClaw prompt injection protection.
Layer 4: Gate Sensitive Operations for Human Review
Not every tool call should auto-execute. An agent with exec permissions can run rm -rf / just as easily as ls -la. An agent with HTTP access can send an email, make a payment, or post to a public API. Some of these actions need a human decision before they proceed.
Shield currently implements the synchronous blocking layer: tool calls matching configured rules are denied immediately and logged. The async approval workflow (pause execution, notify a reviewer, wait for a decision, handle timeout) is the next layer being built on top of this infrastructure.
Four categories of tool calls are candidates for approval gates:
Destructive operations:rm, DROP TABLE, overwriting production configs
Financial actions: payment API calls, invoice creation, pricing modifications
Privilege escalation:sudo, chmod, user creation, access control changes
The before_tool_call hook provides the interception point, and the ShieldEvent schema provides the evidence format. The approval layer adds a notification channel and a human decision loop. For policy design patterns and implementation details, see our guide on adding human approval gates to OpenClaw.
Layer 5: Build a Tamper-Evident Audit Trail
Every event from every layer is recorded in a structured, hash-chained audit log. This is not a debug log; it is an evidence trail designed to survive post-incident scrutiny.
Each event is a single JSON line with the following structure:
The prevHash field is the SHA-256 hash of the previous event's JSON. The first event in a session uses "genesis" as its previous hash. This creates a chain: modify, delete, or insert any event and the chain breaks from that point forward. Verification is a simple linear scan that recomputes hashes and compares.
Events are written to a local JSONL file (~/.openclaw/zedly-shield/shield-events.jsonl) and forwarded in batches to the Shield dashboard (5-second timer, 50-event cap). The local file persists even if the dashboard is unreachable; events are buffered and forwarded when connectivity returns.
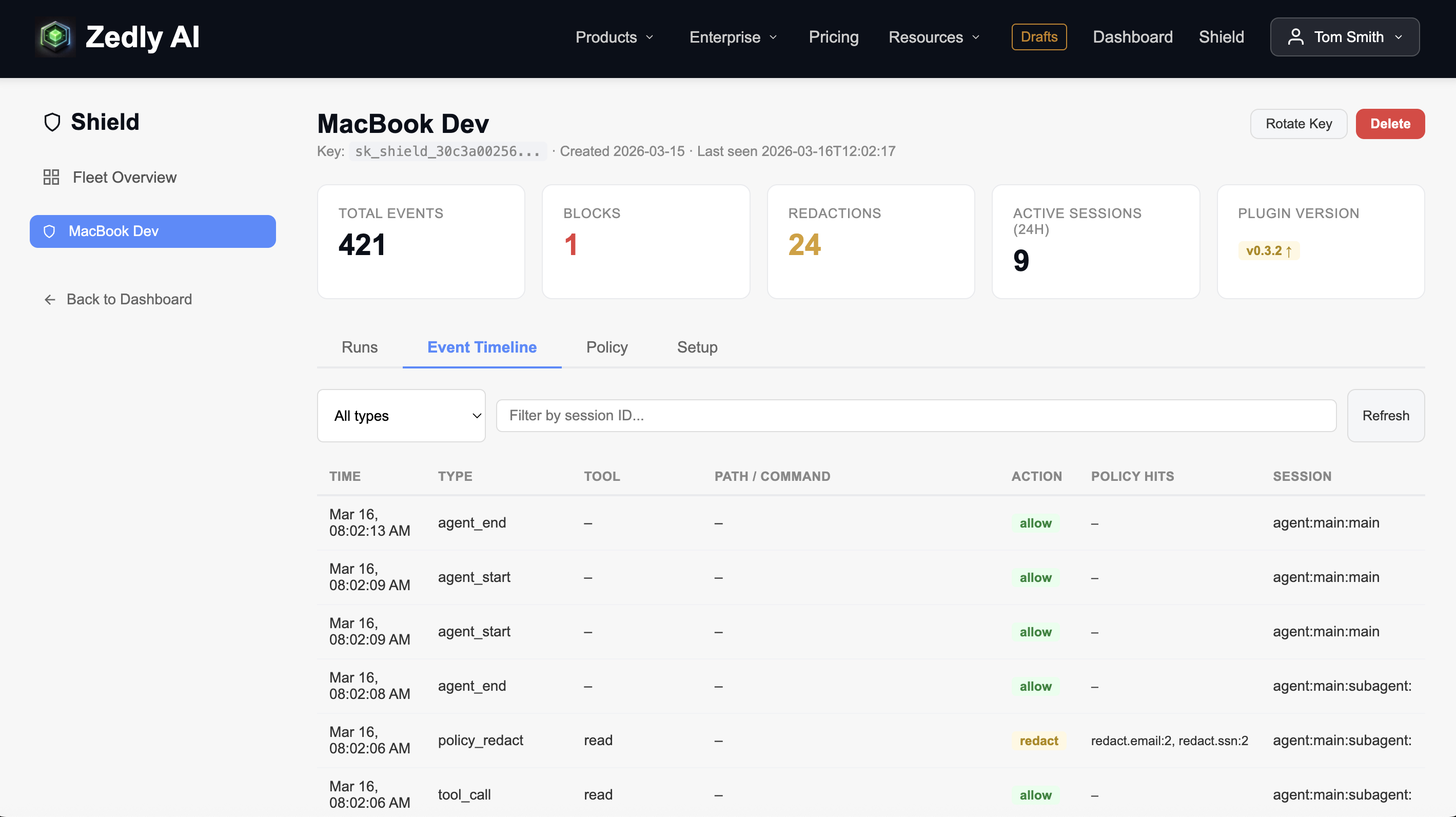
Zedly Shield dashboard: all five hardening layers visible in a single event timeline (click to enlarge)
All hardening features default to true when omitted, except plugins.allowResultModification, which is an OpenClaw-level setting that must be explicitly enabled for PII redaction and injection warning prefixes to take effect.
Harden Your OpenClaw Agents Today
Install Zedly Shield to get tool call blocking, PII redaction, prompt injection detection, and tamper-evident audit logging for your OpenClaw deployment. One plugin, one config block, five layers of runtime hardening from the first event.
Does runtime hardening slow down my OpenClaw agent?
No. Each hardening layer runs inline with the tool call lifecycle, not as a separate network hop. Shell blocking evaluates regex patterns against command strings in under a millisecond. PII redaction scans tool results in a single pass. Injection detection runs 30+ patterns in the same pass. Audit logging appends a JSON line to a local file. The combined overhead for a typical tool call is under 2 milliseconds. Remote forwarding to the dashboard happens asynchronously in batches and never blocks the tool execution path.
Can I customize which tool calls are blocked?
Yes. Zedly Shield ships with three built-in shell blocking patterns (recursive delete, pipe-to-bash, world-writable chmod), but the policy engine evaluates tool name and argument patterns that you configure. You can add custom rules to block specific commands, restrict file write paths, or deny network access from unattended cron sessions. Policy changes take effect on gateway restart without redeploying the plugin.
What happens if the audit log hash chain is broken?
A broken hash chain means that at least one event was modified, deleted, or inserted after the fact. The SHA-256 linkage is designed to make this detectable: any verification tool that recomputes hashes from the first event forward will identify exactly where the chain diverges. Shield's dashboard flags broken chains when events are ingested. The local JSONL file serves as a second source of truth for comparison.
Does Shield work with every OpenClaw tool?
Shield operates at the gateway hook level, not the individual tool level. It intercepts every tool call that passes through the before_tool_call and tool_result_before_model hooks, regardless of which specific tool is invoked. This includes exec, read, write, browser, memory, HTTP, and any custom tools registered with the gateway. If a tool fires the hook, Shield sees it.
Is human approval gating available today?
Synchronous policy-based blocking is live today: tool calls that match configured rules are denied automatically, and the denial is logged as a policy_block event. The async approval workflow (pause execution, notify a reviewer, wait for a decision, handle timeout) is designed and documented on the Shield roadmap. The blocking infrastructure provides the foundation; the approval layer adds the notification channel and human decision loop on top of it.
Ready to get started?
Runtime safety for agentic AI. PII redaction, policy-based blocking, and tamper-evident audit logs for OpenClaw.